
Meta vient de lancer la nouvelle version de ses modèles de langage open-source Llama.
Cette mise à jour majeure, baptisée Llama 3.1, apporte son lot de nouveautés et d’améliorations significatives.
Décryptage de cette annonce qui marque une étape importante dans le développement de l’IA générative.
Llama 3.2 est maintenant disponible, vous pouvez retrouver les nouveautés ici.
Les nouveaux modèles Llama 3.1 de Meta (8B, 70B et 405B)
La famille Llama 3.1 se compose de trois modèles de tailles différentes : 8B, 70B et 405B. Le modèle phare, Llama 3.1 405B, est présenté comme le premier modèle open-source capable de rivaliser avec les meilleurs modèles propriétaires en termes de performances et de capacités.
Les modèles 8B et 70B ont également été améliorés, avec notamment l’ajout du multilinguisme (8 langues supportées), une longueur de contexte étendue à 128K tokens et des capacités de raisonnement renforcées.
Ces modèles permettent de couvrir un large éventail de cas d’usage, du résumé de textes longs aux assistants de codage en passant par les agents conversationnels multilingues.
Principales améliorations par rapport aux versions précédentes de Llama
Quantité et qualité des données d’entraînement
Meta a considérablement amélioré la quantité et la qualité des données utilisées pour pré-entraîner et affiner les modèles Llama 3.1.
Des pipelines de prétraitement et de curation plus poussés ont été mis en place, ainsi que des approches de filtrage et d’assurance qualité plus rigoureuses pour les données de fine-tuning.
Optimisations de l’architecture et de l’entraînement
L’architecture des modèles Llama 3.1 a été optimisée pour permettre un entraînement à très grande échelle (jusqu’à 16 000 GPU pour le modèle 405B).
Meta a opté pour une architecture de transformeur simple mais efficace, évitant les modèles plus complexes type mixture-of-experts (MoE) afin de privilégier la stabilité de l’entraînement.
Le processus de fine-tuning a également été amélioré, avec l’introduction d’une procédure itérative combinant fine-tuning supervisé, optimisation des préférences et génération de données synthétiques de haute qualité à chaque cycle.
Les caractéristiques clés des modèles Llama 3.1
Multilinguisme
Les modèles Llama 3.1 supportent désormais 8 langues, ce qui ouvre la voie à de nombreuses applications multilingues.
Cette capacité a par exemple été mise à profit par SNCF Gares & Connexions pour développer un système d’information et d’orientation des voyageurs dans 6 langues.
Raisonnement complexe et utilisation d’outils externes
Llama 3.1 se distingue par ses capacités de raisonnement avancées, comme le montrent ses excellents résultats sur des benchmarks tels que GSM8K ou MATH.
Les modèles sont également capables d’interagir avec des outils et des API externes, ce qui étend considérablement leur champ d’application (génération de graphiques, récupération de données, etc.).
Génération de données synthétiques et distillation de modèles
La qualité des sorties générées par Llama 3.1 405B est telle que le modèle peut être utilisé pour produire des données synthétiques servant à entraîner et améliorer des modèles plus petits.
C’est une avancée majeure pour démocratiser les techniques de distillation de modèles, jusque-là réservées aux labs disposant de ressources considérables.
Comparaison des prix API avec ChatGPT 4o et Claude Sonnet 3.5
Meta met en avant la compétitivité des modèles Llama 3.1 en termes de coût par token. Voici un comparatif des tarifs API (en dollars par million de tokens) pour l’inférence en temps réel :
| Modèle | Input | Output |
|---|---|---|
| Llama 3.1 8B | $0.30 | $0.60 |
| Llama 3.1 70B | $2.65 | $3.50 |
| Llama 3.1 405B | $5.33 | $16.00 |
| ChatGPT 4o | $5.00 | $15.00 |
| Claude Sonnet 3.5 | $3.00 | $15.00 |
| ChatGPT Mini 4o | $0.15 | $0.60 |
On constate que les modèles Llama 3.1, bien qu’open source, restent compétitifs en termes de prix par rapport aux offres de type API propriétaires comme ChatGPT 4o ou Claude Sonnet 3.5.
Évaluations des performances des modèles sur différents benchmarks
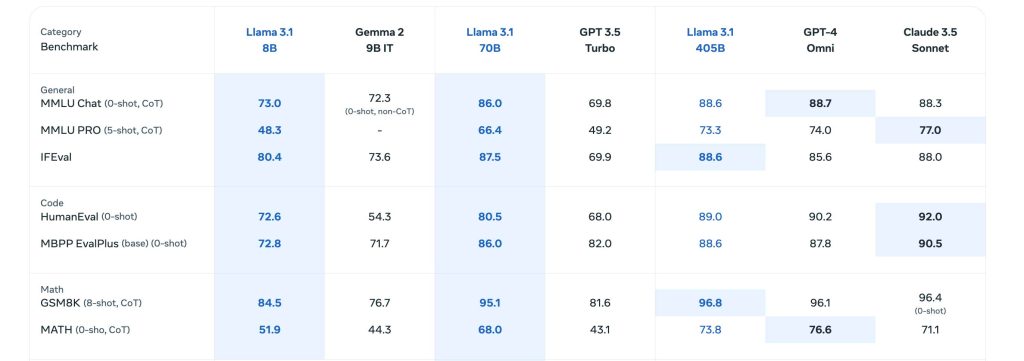
Meta a évalué les performances des modèles Llama 3.1 sur plus de 150 jeux de données couvrant un large spectre de tâches et de langues.
Des évaluations comparatives approfondies ont également été menées face aux modèles concurrents dans des scénarios d’usage réels.
Les résultats montrent que Llama 3.1 405B est au niveau des meilleurs modèles du marché sur de nombreux benchmarks :
- Connaissances générales : 88.6% sur MMLU, 73.3% sur MMLU PRO
- Raisonnement mathématique : 96.8% sur GSM8K, 73.8% sur MATH
- Utilisation d’outils externes : 92.3% sur API-Bank, 35.3% sur Gorilla Benchmark
- Multilinguisme : 91.6% sur Multilingual MGSM
Les modèles 8B et 70B affichent eux aussi d’excellentes performances, avec un rapport capacités/coût très intéressant pour de nombreux cas d’usage.
Mon avis sur Llama 3.1
Nous sommes sur un modèle open source qui va pouvoir concurrencer les petits modèles d’Open AI et Anthropic.
Cependant le fait que le modèle soit open source rend son utilisation légèrement plus complexe et reservé à des utilisateurs avancées, pour le moment.
Potentiel et cas d’usage des modèles Llama 3.1 pour les développeurs
Un écosystème open-source mature
Avec plus de 25 partenaires à son lancement (AWS, NVIDIA, Databricks, etc.), l’écosystème Llama 3.1 offre aux développeurs un large choix de services et d’outils pour exploiter facilement toutes les capacités des modèles : inférence temps réel ou batch, fine-tuning, évaluation, génération de données synthétiques, etc.
Meta propose également un système de référence open-source incluant des exemples d’applications et des composants clés comme Llama Guard 3 (modèle de sécurité multilingue) ou Prompt Guard (filtre d’injection de prompts).
Les efforts de standardisation autour de la Llama Stack visent à favoriser l’interopérabilité entre tous les acteurs de l’écosystème.
Des cas d’usage variés déjà expérimentés
Malgré leur sortie récente, les modèles Llama 3.1 ont déjà été utilisés avec succès dans des domaines très divers :
- Un compagnon d’étude IA déployé sur WhatsApp et Messenger
- Un modèle de langage spécialisé dans le domaine médical pour assister la prise de décision clinique
- Une startup brésilienne qui utilise Llama 3.1 pour faciliter la gestion et la communication des données d’hospitalisation des patients
Ces exemples ne sont qu’un aperçu du potentiel applicatif de ces modèles.
Avec la puissance de l’open-source et les capacités uniques de Llama 3.1, les possibilités sont immenses pour construire la prochaine génération d’expériences IA innovantes et utiles.



Laisser un commentaire